Chapter 11 Microbiome
With the advantage of high-throughput sequencing, we are able to explore the genomes of the tumor-bearing host and the various microbes that reside in the host. It has been reported that the dynamics between microbiota and hosts may influence tumor growth and affect treatment approaches. Notably, gastrointestinal microbiota has been widely recognized for its role in cancer development and its association with cancer therapy response and toxicity. Previous studies have investigated the multiple ways in which gut microbiota influence anti-tumor immunity. For example, the modulation of microbial components helps to enhance T cell response and improve anti-PDL1 efficacy in melanoma patients. In addition, microbial metabolites can provide an energy source for neoplastic progression in colon cancer. Thus, it is essential to decipher microbiota components from the following perspectives: 1) the interactions between disease phenotypes and microbiota; 2) the relationship between treatment efficacy and microbiota enrichment; 3) the involvement of microbiota in condition-specific metabolism pathways; and 4) the application value of microbiota as a diagnostic biomarker. As a whole, the aim of microbiota classification analysis is to help elucidate novel mechanisms of disease development, potentially providing new insights into therapeutic target discovery.
For decades, microbial phylogeny and taxonomy have relied on 16S rRNA sequencing and shot gun sequencing, which contains hypervariable regions as species-specific signatures for microbial identification. To perform computationally robust and effective microbiota classification, researchers have developed reference-genome-based methods from high-throughput DNA or RNA sequencing, such as PathSeq and Centrifuge. PathSeq aligns non-host reads to pre-defined microbial organisms using BWA-MEM alignment, while Centrifuge builds a compressed index merged with unique genome sequences in advance. Although both methods achieve microbiota classification and abundance estimation based on a users’ reference, Centrifuge outperforms PathSeq in meaasures of both memory usage and speed.
11.1 Centrifuge
Centrifuge is a rapid and memory-efficient microbial classification engine that enables fast and sensitive labeling of reads and quantification of species. Centrifuge utilizes FM-index, a compact data structure widely used for short read alignment, to store all the sequence information in the database. For read classification, Centrifuge looks for stretches of long matches greedily between a read and the reference database and scores the taxonomy classification based on the match size. The species or genus with the highest score will be the taxonomy classification result for a read. Reads can be assigned to multiple species, so Centrifuge utilizes the Expectation-Maximization algorithm to quantify the abundance for the identified species. Due to the increasing size of the microbiome reference database, Centrifuge takes advantage of the high sequence similarity between species under the same genus and can compress the reference database.
11.2 Microial classfication from RNA-seq data
The reference index for Centrifuge (bacteria, archaea, viruses and human) can be downloaded from here . The microbiome module of RIMA uses raw fastq reads as input for Centrifuge and a classification report will be generated
centrifuge -x ref_files/centrifuge_index/p_compressed+h+v -p 16 --host-taxids 9606 \
-1 data/SRR8281218_1.fastq.gz -2 data/SRR8281218_2.fastq.gz \
-s analysis/microbiome/SRR8281218/SRR8281218_classification.txt.gz \
--report-file analysis/microbiome/SRR8281218/SRR8281218_report.txt We added a sample name column to each individual report and merged them together. Below is an example of a summary report with sample names added.
sample name taxID taxRank genomeSize numReads numUniqueReads abundance
SRR8281218 Azorhizobium caulinodans 7 species 5369772 6 6 4.85856e-05
SRR8281218 Stigmatella aurantiaca 41 species 10260756 1 1 0.0
SRR8281218 Chondromyces crocatus 52 species 11388132 3 2 0.0
SRR8281218 Sorangium cellulosum 56 species 13907952 3 1 0.0
SRR8281218 Caulobacter 75 genus 0 1 0 0.0
SRR8281218 Planctopirus limnophila 120 species 5460085 1 0 0.0
SRR8281218 Pirellula staleyi 125 species 6196199 2 1 0.0
SRR8281218 Isosphaera pallida 128 species 5529304 1 0 0.0
SRR8281218 Spirochaeta thermophila 154 species 2516433 3 3 0.0
From the results, RIMA selects the top 15 most enriched microbiota according to the Inverse Simpson Index and plots their relative abundance ratio at the cohort level.
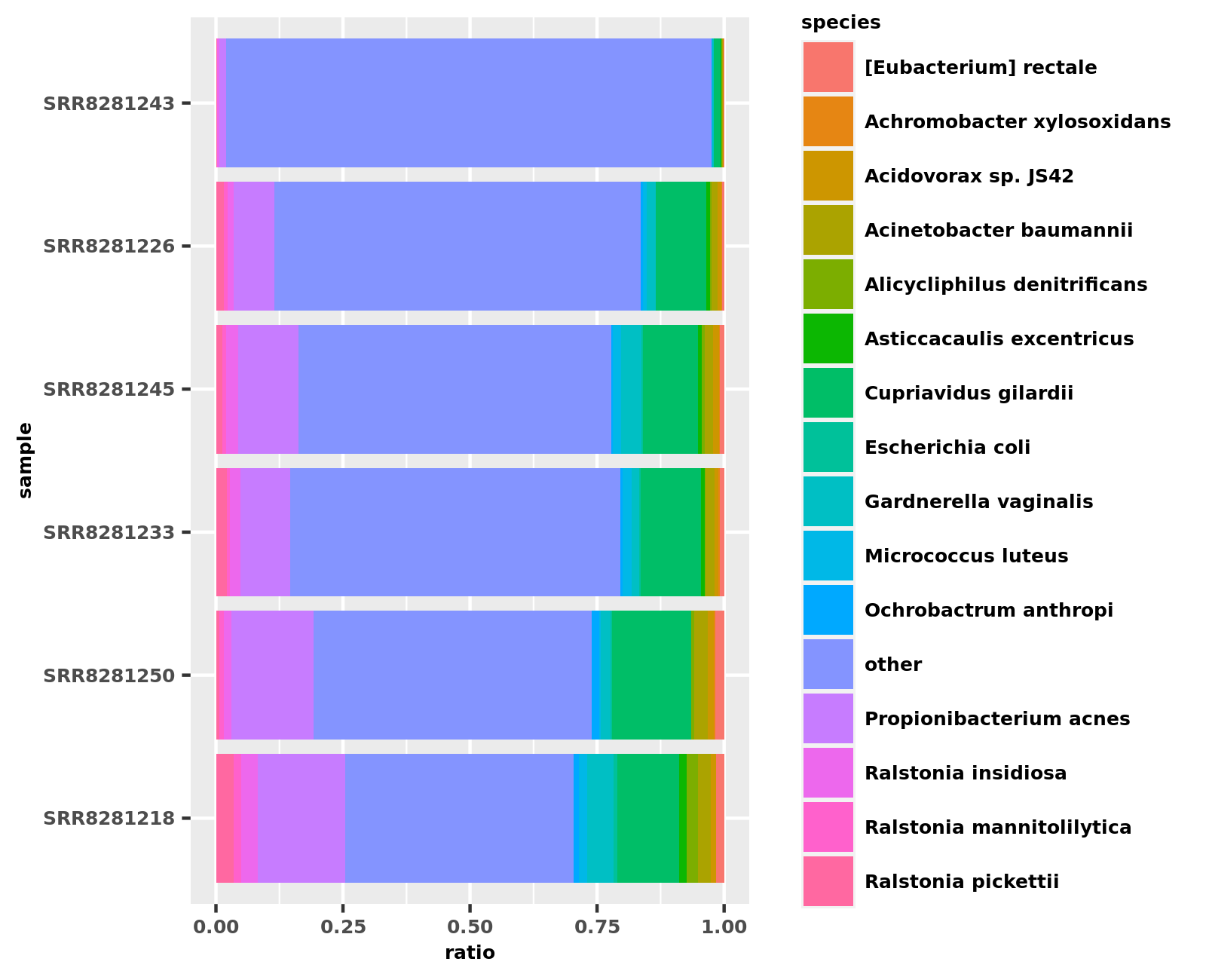
Figure 11.1: Fuison violine plot
11.3 Video demo
11.3.1 We have prepared the RIMA reference folder with the current version we used. You can directly download from Iris server:
# We have nearly 69G reference files
wget http://cistrome.org/~lyang/ref.tar.gz